Why do I find Rust inadequate for codecs?
I wrote this blog post to answer a frequent question that I receive from strangers on the internet: why do I choose to implement codecs in C? The answer is far from straightforward; if you are interested in the details, please read on.
Introduction to Rust⌗
There are many places from which you can learn a lot about the in-depth details of why Rust is an innovative language. I chose to summarise them in this section to give you a brief overview of what I would like to focus on.
Perhaps most importantly, Rust has a powerful trait system that easily generalises dynamic and static dispatch and an ownership model which enforces certain memory-safety-centric invariants. Just to demonstrate a fraction of Rust’s ergonomic design, we will observe this by considering the following example that compares static (i.e. compile-time polymorphism using templates) and dynamic (i.e. runtime polymorphism using virtual functions) dispatch in C++:
This approach is fast, as the compiler can trace and inline the function calls. We lack run-time polymorphism, however, as the templates are instantiated at compile time.
This approach is slower, as the function calls are resolved at runtime through a vtable. We gain run-time polymorphism, hence now we can store different derived objects in a container of base pointers. It’s clear from this example that these two approaches to polymorphism are orthogonal: we design the class hierarchy with either static or dynamic dispatch in mind. Backtracking on this decision in real world C++ code bases is far from trivial. On the other hand, Rust offers us an interesting solution:
The attractive thing about this is that the line (at the syntactic level) between static and dynamic dispatch is blurred. This lets us make use of the shape hierarchy in two separate contexts that are distinguished from their definitions and the usage pattern is rightfully moved from the definition to the concrete snippet of code in the context of which the dispatch strategy matters.
The second part about Rust’s type system is particularly attractive when writing business logic. The principial rule is simple:
A variable may hold a unique reference to a logical object (heap memory region). It is the sole owner of the object and is responsible for its deallocation once it goes out of scope. There may be multiple shared references to the object, but they are read-only and cannot outlive the unique reference. Mutable references are exclusive and cannot coexist with any other reference.
To type theorists and language designers, this is loosely reminiscent of affine types. To the rest of us, it’s a way to ensure that the code is free of mutability-fueled rug pulls and dangling pointers. The practical significance of this is that we can write cover a large subset of memory safety bugs without the need for a garbage collector or a similar runtime system that tracks objects. Of course, such a system is overly restrictive: there are problems that necessitate sharing, which suggests the use of Arc<Mutex<T>>, AtomicUsize and so on. However, as I did not intend to particularly focus on this aspect of the design, I will leave it at that.
Outside of the regular business logic nitty-gritty, Rust also prevents a number of other memory safety bugs. We can demonstrate one important class, buffer overflows, with a simple example:
An example run of this program demonstrates:
1: Set, 2: Read
1
Enter index (0-9)
5
Enter value
12
1: Set, 2: Read
2
Enter index (0-9)
5
12
1: Set, 2: Read
1
Enter index (0-9)
999
Enter value
999
thread 'main' panicked at game.rs:14:7:
index out of bounds: the len is 10 but the index is 999
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
A naive C++ implementation of the same app has a nasty surprise waiting for us:
An example run of this program:
1: Set, 2: Read
1
Enter index (0-9)
5
Enter value
99
1: Set, 2: Read
2
Enter index (0-9)
5
99
1: Set, 2: Read
1
Enter index (0-9)
999999
Enter value
999999
zsh: segmentation fault ./a.out
The magic sauce on the Rust side is implicit bounds checking and the panic!() mechanism that is triggered when the bounds are violated. We can see this by investigating the disassembly of the Rust program:
These two examples showcase Rust’s features that allow it to, for a large part, mitigate a large class of CVEs (about 50-60% of all reported) based on memory safety issues.
Codec implementation details⌗
To sidetrack from the previous topic, we will take a look at some popular compression codecs (PAQ8, bzip3 and LZ4) and their reference implementations. The ultimate goal of this section is to demonstrate core issues that codecs need to solve and also in particular what traditional issues of software engineering don’t exactly apply to them.
Reading the PAQ8L code base, we make a few observations:
- The only place where substantial memory allocation is involved is the
Array<T>class providing aligned memory regions to other classes. - The code doesn’t have out-of-line dependencies, it’s idiomatic and somewhat low-level: for example, binary trees with integer values are implemented using arrays that are indexed by the sequence of bits in the key.
- A lot of objects have
'staticlifetime. A wrapper over this code base would probably pack all of them into a separate class with an otherwise obvious lifetime. - There are many points of failure in the code base, specifically pertaining buffer overflows. For example, in the
Mixerclass that does not check the bounds of the probability or mixer input arrays. - The code is not exactly thread-safe, but it’s not a problem as the codec is inherently sequential.
The bzip3 code base is a bit more suited for embedding, and so is LZ4 (although the latter has a significantly more complex code base). The main takeaways are:
- Both seem prone to buffer overflows (e.g. CVE-2021-3520 for LZ4 and CVE-2023-29421 for bzip3; latter due to an overly lax bounds check).
- bzip3 depends only on libsais and libc, LZ4 depends only on the libc.
- Both are thread-safe and offer a reasonable error handling interface.
- A lot of the code pertaining the logical object handling is rather simple (the objects are usually arrays with clear ownership and lifetime rules).
All of the code bases place a significant emphasis on performance, but it’s very unlike performance most of us are used to. Optimisation in the business context generally focuses on the low hanging fruit like improving algorithmic logic and mainly targetting “obvious” bottlenecks. On the other hand, codecs like bzip3 are already linear in the size of the input and use state-of-art algorithms (e.g. SAIS for suffix sorting) so the performance optimisation is more about making the code base more cache-friendly, reducing the number of branches in the code, improving their predictability, vectorisation, etc.
Why I choose C⌗
I wanted to write this blog post to bust common misconceptions that programmers have about Rust and codecs, namely I observe the following:
- Codecs have next to no business logic moving parts. Most of it is the low-level nitty-gritty, which Rust is not particularly good at.
- Bounds checks are rarely performed in the compiletime and we have to pay their price at the runtime. This is a significant performance hit for codecs.
- The ownership model is not particularly useful to codecs. It is usually painfully clear who owns what (it’s usually the “god structure” of the codec owning everything else) and for how long (between calls to
bz3_newandbz3_free). - Rust is much more ergonomic for the typical workload than C or C++, but a fundamentally unobtrusive language is more conducive to implementing low-level performance-sensitive code.
In my mind, this is not an issue of safety: it would be a clear and added benefit if codecs were safe, but Rust does not provide adequate safety in acceptable performance (read on). And hence my decision stems purely from the fact that C is more ergonomic for this specific kind of low-level code.
It’s easy to optimise in C due to the relatively small amount of indirection and abstraction at our disposal. However, not even that is often enough: as a case study, I offer you the xpar project. Compilers are notorious for not handling certain things well and one of them is the CRC32-C intrinsic, as demonstrated by GCC output for a 3-way ILP CRC32-C implementation:
It was difficult to coerce the compiler to output efficient code for a LFSR implementation that powers the BCH-view RS encoder in xpar. The C implementation is simple:
However, my attempts at vectorising this using intrinsics have failed as the compiler was very skeptical of the idea that byte-wise element shifts over vector lanes are going to be faster than spilling and restoring the output vector, which caused it to slightly deoptimise my code at every attempt. Ultimately, I have resorted to writting raw assembly to get the performance I wanted (read the full story here):
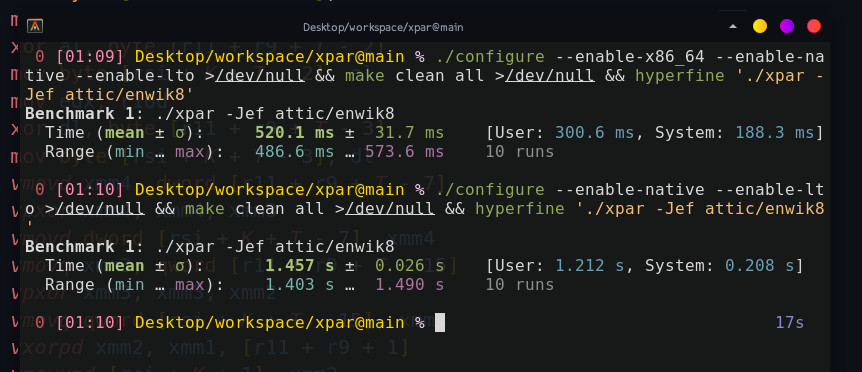
It is possible that far into the future the compiler will be able to spot this idea and generate better code than the one I wrote. However, this is inadequate in my mind, as distribution maintainers and other suppliers of software usually use stable or outdated versions of compilers (looking at you, Debian!) causing all of the new and shiny compiler optimisation efforts to go down the drain.
Note on safety⌗
Many things about codecs make it more of an art than a science: we want to place ourselves somewhere on the curve of resource usage to compression ratio. Inefficient implementations move us towards more complex algorithms with better compression ratio needlessly.
Bounds checks on inherently serial architectures do incur additional overhead. While compilers can often hoist them via an optimisation called strength reduction, it is often not sufficient. To demonstrate this, we will enable bounds checks for the bulk of the PAQ8L code base (with and without NDEBUG) and measure the performance difference. We will use clang-19 as it matches the underlying code generation platform of rustc:
% clang++-19 paq8l.cpp -O3 -o paq -w -DNOASM # Assertions OFF
% hyperfine './paq -5 paq8l.cpp'
Benchmark 1: ./paq -5 paq8l.cpp
Time (mean ± σ): 5.196 s ± 0.390 s [User: 5.090 s, System: 0.105 s]
Range (min … max): 4.584 s … 5.744 s 10 runs
% clang++-19 paq8l.cpp -O3 -o paq -w -DNOASM # Assertions ON
% hyperfine './paq -5 paq8l.cpp'
Benchmark 1: ./paq -5 paq8l.cpp
Time (mean ± σ): 5.999 s ± 0.642 s [User: 5.886 s, System: 0.110 s]
Range (min … max): 5.000 s … 6.794 s 10 runs
We have observed a ~13.3% slow-down, which is significant enough to warrant a second thought on whether the bounds checks were a good idea in the first place. A similar test could be performed on the bzip3 code base, but the result would be even more disasterous. Many invariants about PAQ8L are easy to prove to the compiler as we index fixed-size memory regions with approperiately-masked indices, hence the checks can be elided (in general). This is not the case for bzip3, where many of the memory areas have a runtime-determined size that would be difficult to track during the compile-time in order to hoist checks.
Another important pain point is the unnecessarily fuzzy definition of a bug. Practically speaking, fprintf + abort goes a long way over Segmentation fault. that proves itself impossible to debug. But such behaviour is still unacceptable from a library perspective: a library should never, ever call abort or otherwise terminate the program. This would lead to a denial-of-service attack on whatever is the application that chooses to wrap such a library. While C++’s std::vector<T>::at() throws an exception which can then be caught and cleanly relayed to the application, a panic!() or an abort() are much more annoying to catch and handle. Moreover, panic!()’s are hiding even in the most innocious places like unwrap() and expect() calls, which in my perception should only be allowed in unsafe code, as they introduce a surface for a denial-of-service attack. In such a scenario, an attacker could craft a malicious input that would cause the program (e.g. web server) to panic and terminate, which in turn would interrupt the service for all other users.
In my mind, a more advanced memory-safe system will likely overtake Rust and become adequate for the task of implementing codecs and other low level tools (perhaps integrated with a theorem prover and a proof assistant that lets the programmer clarify the assertions, preconditions, postconditions and invariants). However, I will stick with C for now. Ultimately, a lot of this boils down to personal preference, so try to not harass strangers online for their choices.