June 2025⌗
26 June:
If servicing public debt grows too costly, governments should raise revenue not through taxes on work or spending, but by taxing vanity wealth.
25 June:
Words ought to be a little wild, for they are the assault of thoughts on the unthinking.
22 June:
Updated my computer set-up to use Enlightenment E16 with custom multi-monitor, keyboard shortcut and tiling support that I implemented.
19 June:
The most appealing line of thought in Transhumanism is the one that suggests leaving my disfigured body behind.
15 June:
I start my day with looking in the mirror and deciding if I want to be depressed or hopeless today.
9 June:
In an economy with its own fiat currency, the monetary authority and the fiscal authority can ensure that public debt denominated in the national fiat currency is non-defaultable, i.e. maturing government bonds are convertible into currency at par. With this arrangement in place, fiscal policy can focus on business cycle stabilisation when monetary policy hits the lower bound constraint. However, the fiscal authorities of the euro area countries have given up the ability to issue non-defaultable debt. As a consequence, effective macroeconomic stabilisation has been difficult to achieve.
- Monetary-fiscal interactions and the euro area’s vulnerability, European Central Bank Bulletin 2017.
Author’s commentary: when the ECB tells you that Euro makes no sense, you should listen.
8 June:
I have extracted some of my journal notes dating to before 2022. Enjoy. I mourn my childhood innocence.
7 June:
I desire to be immortal on the spiritual level.
6 June:
On an intellectual level this is a lazy day, on a practical level i am nearing 90k SLoC on my thesis.
May 2025⌗
24 May:
Considering getting cosmetic surgery, but saving up/getting the loan might be the hard part.
22 May:
Oh, yes, the acknowledgments. I think not. I did it. I did it all, by myself.
21 May:
I will start a home-brew Club Mate production line in Canada.
20 May:
Technology discloses the active relation of man towards nature, as well as the direct process of production of his very life, and thereby the process of production of his basic societal relations, of his own mentality, and his images of society, too.
19 May:
Looking forward to moving to Canada. I hope that everything works out.
15 May:
These days I am focusing on writing down my thesis, which is currently taking a significant portion of my time. As such, I had to put OSS and blogging on the backburner.
10 May:
No words can describe how shamelessly awful most people I met here in Germany are. Everywhere else I lived in, it would be considered unacceptable to be so rude and obnoxious about someone (whom you presumably don’t know) being “ugly”.
April 2025⌗
30 April:
Passed by thesis seminar today! I am pretty sure that I hold the faculty’s record for the longest seminar talk - about 6 hours.
18 April:
At Revision 2025!
10 April:
The progress on my book is starting to feel a little stale.
3 April:
I do this not because it is easy, but rather because I thought that it will be easy.
2 April:
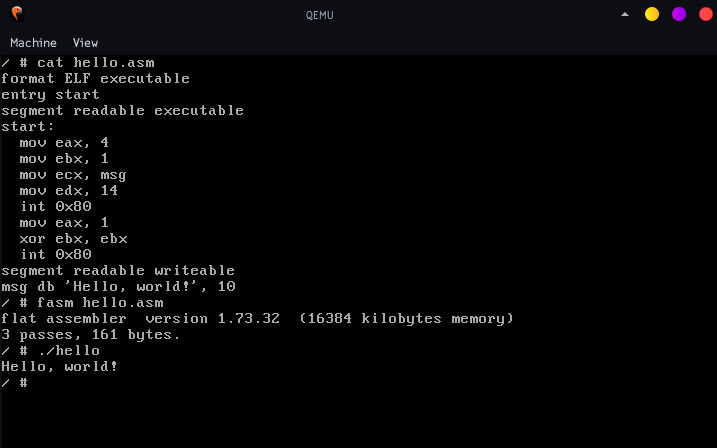
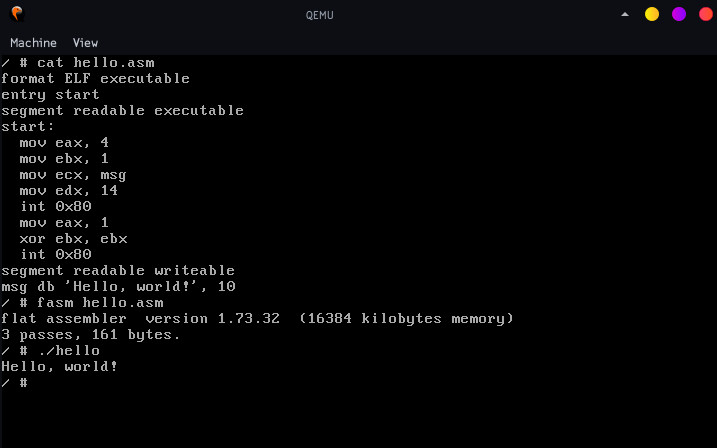
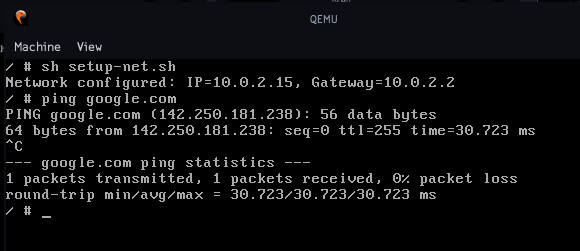
My talk for 19 Sesja Linuksowa: Fitting a modern Linux distribution on a floppy disk (1.44M) using the magic of custom compression. Newest x86 Linux kernel, BusyBox, Flat Assembler bundled. The kernel supports networking, comes with vim, sed, grep, find, httpd, wget, …; PCI/FAT32/ATA/SATA support.
March 2025⌗
30 March:
I can’t possibly convey how fun working with bioinformatics tool suites is. To a newcomer, they all look pretty okay, and all the standard stuff seems to be already there.
You try running a simple sequence alignment program, but instead of standard input/output, it insists on using six different configuration files in a format no other tool understands and uses semicolons for FASTA headers.
You grab a genome assembler, but it only works with a very specific version of an old library that isn’t maintained anymore. The documentation tells you to “just install it from this FTP link”, which is of course broken.
You run a phylogenetic tree builder, but the output file is in a format that no visualization software can read - except for one program from 2003, which only runs on an old version of Java that conflicts with everything else on your system.
You take a look at the variant caller. It requires chromosome names in the format
chr1, but another tool in your pipeline needs them as just1, and neither has an option to switch.The genome assembler hasn’t been updated since 2012, but everyone still uses it because the “modern alternative” requires 200GB of RAM and crashes silently when it runs out.
And on you go. Every tool mostly does what it’s supposed to, but each one has its own weird dependencies, its own obscure input formats, its own inexplicable quirks. There’s no clear problem with bioinformatics software as a whole; all the essential tools technically exist.
Now imagine you meet millions of bioinformaticians who tell you, “Well hey, what’s the problem? This is what we’ve always used, and it works fine!”. And they show you their pipelines, held together with ten different shell scripts, manual file renaming, and a README that just says, “Run this on Ubuntu 16.04, trust me”. And you point out that one of their scripts has a hardcoded file path to someone’s home directory, and they just say, “Yeah, that happens sometimes”.
21 March:
It has come to my attention that for the past few months a few individuals have set to come up with fake male names for me and edit secondary sources online that mention me. I have no idea why they do this, but I find it amusing and I have suspicions.
Compression and cryptographic programming languages are pretty easy to become a world-class expert at, and I feel very sorry for people whom this makes insecure about themselves. I understand feeling bad that a 20 (then 15) year old immigrant from the middle of nowhere is better than you at just about everything. But there will always be people better than you and better than me. One part of growing up is accepting this.
11 March:
Exceptions have the added benefit of stack traces. Optionals or error tuples present the issue but conceal the cause. Languages that offer monadic error handling like to hide the origin of the failure. Sometimes this is done also because such a stack trace is difficult to reconstruct in a lazy setting and the traces need unwound to memory alongside thunks.
Hegel said somewhere that all important personalities and historical events repeat twice. He forgot to add: once as a tragedy and the other time as a farce.
10 March:
I had exceptional luck travelling to Mallorca. I was not stopped by security and it took only a few minutes. After me it took a while, since they had to swab some 70 years old couple’s stuff to make sure they’re not bringing hard drugs or explosives onboard. The grandma ahead of me got groped tip to toe.
9 March:
I may participate in Revision (the demoparty) this year. It’s happening in Saarbrücken mid-April.
8 March:
Googling anything related to (GNU) bison gives me, a programmer with a 69420 year history of googling programming stuff, the stupid fucking animal.
5 March:
Apparently debian has a “tracker-miner-fs” process running in the background and it’s something completely normal (gnome search indexer). I suggest debian developers run a process that does nothing called “rootkit-trojan-net” just to keep users on their toes.
4 March:
I don’t have an ice cube’s chance in hell of finding lifelong happiness unless I can find a woman as ugly as myself.
2 March:
I think I would be much happier if the underlying structure of the universe were significantly different.
1 March:
The belief that theoretical computer scientists are uniquely intelligent has done unimaginable damage on society.
February 2025⌗
23 February:
It took me months to settle on this, but TeX Gyre Bonum seems to be the best font for typesetting my book.
22 February:
If Americans had a cookie for every lie they told about Europe, the Danes would be working two shifts on Ozempic production.
21 February:
I have a degree in creative memory management.
20 February:
19 February:
Let’s decrease deficit and the public debt. In order to do that, we decrease government spending. Then:
Decrease spending -> the private sector and consumers have less money -> demand goes down -> supply goes down -> GDP goes down -> tax income goes down -> deficit goes up
The deficit (i.e. private surplus) among all branches sums up to zero. Every liability (debt) is someone’s asset. Every spending is someone’s income.
18 February:
Every -person chat room has an associated -person chat room.
15 February:
My taste in luxury is sourdough and aged cheddar.
14 February:
I wish that university education was more about they joy in pursuit of knowledge rather than drilling, grinding and depressing yourself over whatever you’ve been bequeathed to study.
9 February:
I really want to start an old-school forum :(.
8 February:
I always wanted to learn Cantonese, but then I realised that I have no reason to do so other than the fact that it seems interesting. Because of that I will have no motivation to study further because my existing life obligations that force me to learn a lot.
6 February:
Archive files (.tar, .zip) and file systems (ext4, NTFS, FAT32) are two sides of the same coin. Both provide fundamental facilities for hierarchical data storage, record file metadata, support basic file system operations (add, remove, modify). Some file systems do versioning (btrfs), some archivers do too (zpaq). Some natively support compression (zfs), but so do archivers (zip). The crucial difference between both is thus the use case. Most file systems are used for live infrastructure (FAT32, NTFS, ext4). Some file systems are used for seekable, immutable and compressed storage (squashfs, cromfs). Then, archives are used for data meant to be just compressed and extracted.
3 February:
% # 32-bit ELF Linux quine, 53 bytes. % ./a.out | xxd 00000000: 7f45 4c46 0100 0000 0000 0000 0000 0100 .ELF............ 00000010: 0200 0300 2e00 0100 2e00 0100 0400 0000 ................ 00000020: b004 b235 cd80 584b cd80 2000 0100 4341 ...5..XK.. ...CA 00000030: c1e1 10eb eb ..... % cat ./a.out | xxd 00000000: 7f45 4c46 0100 0000 0000 0000 0000 0100 .ELF............ 00000010: 0200 0300 2e00 0100 2e00 0100 0400 0000 ................ 00000020: b004 b235 cd80 584b cd80 2000 0100 4341 ...5..XK.. ...CA 00000030: c1e1 10eb eb
January 2025⌗
28 January:
Why is the Internet no longer like it used to be before? Leading explanations attribute the death of individual, personal and free expression to the rising popularity of the Internet, commercial/corporate influence and centralisation. Without doubt, these are the most significant factors. But is this the whole story? One frequently overlooked factor is simply that the modern and more accessible internet culture has de facto destroyed self-expression.
Large masses of people often converge to blobs formed by simple addition of homologous magnitudes, much like potatoes in a sack form a sack of potatoes. In such a setting, the individual lacks identity. The concept of “cringe” has destroyed the concept of self-expression. Irony, the most popular defense mechanism against being considered “cringe” changed the landscape of the Internet.
Authenticity necessitates vulnerability and vulnerability attracts dead-eyed, far gone, meta-ironic magnitudes that project their aversion to vulnerability as “ironic shitposting”, i.e. shunning expressions of authenticity until everyone is many layers gone into defensive irony.
23 January:
Every morning I take one big sip of coffee and then pour the entire cup into the sink. The sink is for putting things into. Not for taking things out of.
22 January:
Own the libs with ONE SIMPLE TRICK:
find / -type f -name '*.so' -exec sudo chown $USER:$USER {} \;
20 January:
All the best programming languages come from Canada: APL, PHP, Java.
8 January:
The tradition of all dead generations weighs like a nightmare on the brains of the living.
5 January:
Today I’ve been thinking about mental/human memory algorithms for day of week computation. Many of them feel wrong because
- They require a lot of memorisation.
- They are restricted in scope (e.g. they make you memorise the century key).
- They require large number arithmetic.
My method:
Pros: Only 16 digits to remember, which are further easy to remember due to their patterns. A very small amount of working memory is required: First we need to remember y,m,d; after
int g = t[m+3] + d; y -= m < 3;we only need to rememberg, y. Then, y %= 400 is easy to do in memory. The remaining computations operate on two-digit numbers. After the that line we only remember f and g. Which are then summed and taken modulo 7. The algorithm works for every forseeable date.
December 2024⌗
31 December:
How to check divisibility by 65521 without a remainder operation:
30 December:
The belief that men not moved by a sense of duty will be unkind or unjust to others is but an indirect confession that those who hold that belief are greatly interested in having others live for them rather than for themselves.
20 December:
abysmal /əˈbɪzml/
- extremely bad; appalling. similar: very bad, dreadful, awful, terrible.
- literary: very deep. similar: profound, complete, utter, thorough.
16 December:
Merry Christmas!
15 December:
How I see APL is as an inherent and obvious product of programming language evolution.
Once you start with Assembly and get good enough, you notice that you no longer think in terms of opcodes, GOTOs or registers; instead, you think of variables and high-level control structures (if this then that). translating mental pseudocode to assembly becomes tedious.
Then, we saw the advent of higher level languages like C: you no longer have to spend so much intellectual effort on translating ideas into code, as the compiler can do it better. Further, the gist of the idea can be understood better by most programmers by seeing more structured code than assembly.
After that, we realised that writing a hash map from scratch in every source file is also an inefficient use of programmer time, as humans find it easy to conceptualise basic data structures like a dictionary. Unfortunately, this is where most programmers nowadays plateau: when writing code, they think of for loops, hashmaps and if statements. The average programmer deludes themselves that they are not bottlenecked by their typing speed or their skill at translating abstract ideas into code: they see programming as the act of such translation without regard to the art of reasoning in abstraction.
The CS-savvy programmers discover functional programming. They learn about recursion, which greatly simplifies many structural operations. But at some point they notice that recursion as a concept is powerful and low level: difficult to debug, difficult to reason about, difficult to match patterns on, verbose. At this point, they discover recursion schemes and become efficient at juggling around maps, filters, scans and reduces. They make it easy to do basic strength reduction and optimisations, change existing behaviours and add components to data processing pipelines, on top of being rather easy to reason about to a skilled programmer. But many people don’t ever get to this stage - see the amazement at “ngn scans”. And then the ultimate step of this evolution is noticing that most of these maps that hide recursion deep down are not necessary and if only data was arranged in arrays, the loops could be tucked away inside of even the most primitive operations. This is what makes APL relevant and so representative of human thought - it minimises the amount of intellectual effort that is required to turn abstract ideas into code. It lets programmers focus not on the bread and butter of computer science but further develop ideas and improve as scientists and problem solvers.
But - as I mentioned before, most people stop at the third stage: they can never efficiently reason about abstract ideas or very high level code, because they’re not representative of their mental model which was shoehorned into ALGOL-style programming. They never solve problems abstractly - they think in terms of code, which has high degree of cognitive overload due to the need of mentally materialising all the ceremony and magic that’s related to inherently verbose mainstream languages. And this is why they never feel bottlenecked by the speed at which they write stuff. Hence, APL simply doesn’t work in a commercial, group setting. Readability in the common sense is a dial that you can twist between programmer convenience and efficiency and how digestible the code is to the average person. Unfortunately, you will be hiring average people and you will not meet two efficient programmers with the same mental model, so the idea of abstracting away reality doesn’t work. You have to agree on the lowest common denominator in terms of abstraction levels that makes working comfortable for everyone: it’s easier to adopt a (simplified) shared common mental ground than get everyone to agree on the local zen of code.
But maybe forcing people to agree on the “zen of code” would be a good thing: so-called readable code is meant to simplify onboarding and development of code because programmers don’t need to spend a long time figuring out how the whole thing works. That may be a bad thing: programmers may delude themselves into thinking that appearing to work is the same as working, and hence introduce subtle bugs into the code base that they don’t really understand, which the upfront familiarity would have de facto required. This is a common trend in programming right now. I don’t agree with it, because every code base builds up their own non-standard set of primitives in utility classes that take a long time to grasp, while APL regardless of where you use it is mostly the same and idiomatic due to the fact that primitives actually do things.
Bottom line: Is becoming more efficient at programming and abstract reasoning through the use of better tooling a ever goal for programmers? There is no tangible benefit from being specifically faster at greenfield programming. I find it desirable because I am a young programmer and first and foremost a scientist, but I would imagine that my more senior colleagues don’t have a reason to chase this - they work on established code bases that grew hairs and limbs over the years, just like every commercial/long-term project and don’t ever have the drive to return to greenfield programming.
13 December:
Rediscovery: a reasonably good RNG in under 300B of brainfuck code:
>>>+++[<+++++>-]>+[<[-]<[>+<<<+>>-]<<[>>+<<-]>>>[<<<+>>>-]<<<[>>>++<<<-]>>>[<+>-]<[>+<<<+>>-]<<[>>+<<-]>>>>>+++++>+<[<<<<<+>>>[>>>>>+<<<<<-]>>>>>[-[-<<<<<+>>>>>>]<]<[>]<<-]<<<<<[>>>>>+<<<<<-]>>>>>>-<[-]<<[<->-]<<[>>+<<<+>-]<[>+<-]>+>>[>>>>>+<<<<<-]>>>+>>[-[-<<<<<+>>>>>>]<]<[>]<-<<<[<+>-]<.>>]
5 December:
We should combine Malbolge, Haskell, CUDA, MIPS assembly, Lean and Verilog to create a new fantastic programming language.
August 2024⌗
16 August:
Progress on Data Compression in Depth:
106 118 2777 ./main.tex 2632 27535 184506 ./content/chapter3.tex 3635 37047 273143 ./content/chapter5.tex 33 321 2255 ./content/appendix.tex 14 796 5391 ./content/foreword.tex 484 5366 35317 ./content/chapter7.tex 1316 11660 77651 ./content/chapter0.tex 1488 11531 76060 ./content/chapter4.tex 1460 11414 83695 ./content/chapter1.tex 3021 27776 186147 ./content/chapter2.tex 2112 15631 113221 ./content/chapter6.tex 247 3365 22936 ./auxiliary/scratchpad.tex 16548 152560 1063099 total
15 August:
Picture an instant messenger (e.g. Discord). Open a random channel in a STEM-related server.
“A: Hey, I need help with problem [X]. Please DM me.” “A: Hey, I need help with problem [X]. B: Sent a DM.”
Sounds familiar?
It has always puzzled me why would people rather offer help via direct messages instead of discussing the subject in public. After all, this way the answer can benefit everyone reading who may be asking themselves the same question. Also, there may be some people who will ask follow-up question, and yet another person to answer them. Perfectly logical.
Now, step back for a second. Depending on how long you have been on the internet, this may annoy you even more than some of the freshly-recruited STEM hobbyists. Since a lot of programming forums are dead, spammed with useless content or poorly moderated, it’s becoming more difficult to just look the the question online. Have you ever found yourself joining a community and immediately after searching for your problem in the message logs? When you really think about it, is it actually true that there will be many people who will benefit from the answer? After all, we can’t efficiently index Discord servers too. And what is the likelihood that two people with the exact same problem will be browsing the channel at the same time?
Someone demonstrates a simple C program along these lines:
Contrary to what they expected, this program prints 0012 FFFFFFAB. Why does this happen? Pretty simple - so you start explaining: printf wants to print a variable of type unsigned int, but the variables you have declared are signed chars. So the signed char has to be widened to an int, but in 2s complement 0xAB is a negative number, hence to preserve the sign it’s padded with 1 bits at the front (i.e. sign extension; compared to padding with zero bits - zero extension). You suggest that marking the variable as unsigned char will solve the issue.
Before your suggested solution could even be tested, someone interjects. After all, the C standard does not guarantee the signed number representation. Further, the standard doesn’t specify whether a char is signed or unsigned, so it’s incorrect to assume that it’s signed. You are wrong.
Annoyed yet? And you have been unlucky too, because the pedantic interjection is actually technically correct. These kinds of exchanges stem from the (exceedingly common!) pedantry in educational settings coming from complete misunderstanding of didactics. Practically speaking, simple problems that have difficult explanations usually need some degree of simplification to be digestible by a beginner. Unfortunately, such simplification, for a sufficiently simple subject, leads to you technically saying things that are not entirely correct. This makes “safe” explanations really fucking difficult, if not impossible.
Finally, the flip side of this is the fact that pedantry and inability to temporarily accept axioms never actually leads to learning. Learning is a deeply unscientific process, driven by empirical experimentation, simplification and iteratively patching the voluntarily created gaps in one’s knowledge. In other words, you probably want to learn like BFS with pruning, not like DFS.
Takeaway: People would rather explain simple problems in private to avoid having to deal with idiots butting in.
June 2024⌗
1 June:
Really happy with how my book is coming together. I spent a lot of time on it. Maybe publishing it is not as remote as I thought it will be. Also happy pride month.
May 2024⌗
23 May:
Every mathematician believes that they are ahead of others. The reason they never state this in belief in public is because they are intelligent people. On the contrary, many programmers do state such a belief in public, because the median programmer is not intelligent.
22 May:
Typesetting my book got me crying a few times.-
20 May:
I must be the only person on the planet who eats olives straight out of a jar as a snack. I love being an independent adult who lives alone.
13 May:
German business model was based on cheap energy from russia, cheap subcontractors in eastern eu and steadily growing exports to china. all three are gone by now, but german politicians are still stuck in a world that doesn’t exist anymore. So now after the whole country has been turned into a smelly coal-burning pit thanks to fake reports about nuclear and understating the coal plant emissions by 200x, there’s no going back and germany is sooner or later going to level with eastern european countries.
8 May:
wow, Windows ACLs are real nasty to work with from within C and WinAPI.
5 May:
The mistakes i made when developing bzip3 are as follows:
- applying LZP front-to-back (mistake shared by most codecs)
- no end of file marker
- RLE stage (it looked lucrative at first when i tested it on some corpora, but ultimately it’s a mistake)
- following LZ4’s idea of a frame and block format (people get confused to hell and back when they learn that bz3_decompress uses a different format than the bzip3 CLI tool; tldr the API function knows more about the input so it can compress more efficiently, while the cli tool has to take pipe input)
- using a strong statistical model by default without a knob to turn it off and replace it with something faster.
- not taking advantage of block size reduction on known input sizes
April 2024⌗
29 April:
If you are working on a project, do your best to never burn a bridge. Try to not take limiting design decisions unless you are absolutely sure of them. Document future potential for improvement, but focus on getting a MVP first.
23 April:
I came back home! A few highlights of my trip to wroclaw:
- horrible weather. i packed short shorts, it was under 5C consistently the whole time, windy and rainy.
- the organisers were really nice and my talk went great
- got some free stuff from OVH, including a pizza slicer
- got confused for a nun once. when i turned around, a guy in his early 40s started apologising.
- got delayed for 3hrs by border control. i don’t even know what they were doing. with this amount of time they could’ve checked everyone’s rectal cavity for cocaine multiple times over.
- hotel room was nice as always, managed to book something close to the old town & the university itself.
- public transport was free on the day of my talk because of elections. i went on morning and afternoon walks, at some point got cold and figured that i need to catch the streetcar. then someone has politely informed me that it’s free. it’s only a shame that streetcars are not heated.
- i explored a bit more of the city and wroclaw actually seems somewhat pretty and clean.
16 April:
Controversial stance: I really hate grug developers. Especially the species that will never learn how anything computing actually works. Like a hashmap/hashset, vtables, literally anything. They will discourage others from learning it because it’s useless, and will not learn it themselves because if you roll your own hashtable then it will be buggy.
15 April:
abysmal /əˈbɪzml/
- extremely bad; appalling. similar: very bad, dreadful, awful, terrible.
- literary: very deep. similar: profound, complete, utter, thorough.
14 April:
My life feels like a kaleidoscope. Every time it twists, it becomes completely different from how it used to be.
13 April:
One thing i feel bad about: none of my current projects that are ongoing are public so far. I feel like the stuff i don’t put on my github gets excessively little publicity. Actually publishing stuff gives me a sense of fulfillment in that i actually made something and it’s gotten to the state in which it’s usable, a state which is usually not shared with the stuff I deliberately choose to not publish. Also working on my book is a neverending process. I poured so much time into that.
“Don’t take criticism from people whose advice you would not follow” is something i should start living by. It’s difficult to tune out the noise and not be let down by it, and I should actually crack on the things that need to be done.
12 April:
Planning to spend my evening tomorrow with my friends having a board game night together. It kinda sucks that so little people even want to play board games. Almost everyone i know would rather play something on their pc. My jet lag from having been to canada for a month has still not healed. Hopefully it gets better because I have some errands to run.
6 April:
Benjamin installed more RAM in my computer, now I have 40GB. Relatedly, the amount of Turing machine approximations available on the market is rather disappointing.
5 April:
Favourite song of today: Toshiki Kadomatsu - Fly by day
4 April:
Today we ate dinner in the CN Tower restaurant. It was really good. The place where you eat spins around so you can see the whole city. Unfortunately, during our booking it was raining, so you couldn’t see much.
2 April:
Two-day long city break starts today, we plan to catch the train at 12:00 and stay there for ~2 days. Then on the 9th of April I have to go back home in Germany :(.
1 April:
We made pizza for dinner. It was all gone in ten minutes.
March 2024⌗
23 March:
Hexdump of a 526-byte Mersenne Twister program (ELF64, takes decimal seed as input, writes output as a sequence of 4-byte LE fields). Approx. 1.5GiB/s on my machine. I wonder if I can do better.
00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............ 00000010: 0200 3e00 0100 0000 7800 4000 0000 0000 ..>.....x.@..... 00000020: 4000 0000 0000 0000 0000 0000 0000 0000 @............... 00000030: 0000 0000 4000 3800 0100 4000 0000 0000 ....@.8...@..... 00000040: 0100 0000 0700 0000 0000 0000 0000 0000 ................ 00000050: 0000 4000 0000 0000 0000 4000 0000 0000 ..@.......@..... 00000060: 0e02 0000 0000 0000 ce2b 0000 0000 0000 .........+...... 00000070: 0010 0000 0000 0000 488d 358f 0100 0048 ........H.5....H 00000080: c7c2 1000 0000 0f05 31c0 4489 c10f b60c ........1.D..... 00000090: 318d 51c6 83fa f672 0d6b c00a 41ff c001 1.Q....r.k..A... 000000a0: c883 e830 ebe4 8905 6221 0000 4831 c948 ...0....b!..H1.H 000000b0: ffc1 4c8d 0555 2100 0048 81f9 7002 0000 ..L..U!..H..p... 000000c0: 740f 69c0 b517 0000 4189 0488 48ff c1eb t.i.....A...H... 000000d0: e866 bb70 0231 c041 b900 0000 804c 8d15 .f.p.1.A.....L.. 000000e0: 2201 0000 4831 ff48 ffc7 6681 fb70 027c "...H1.H..f..p.| 000000f0: 3f31 c948 81f9 e300 0000 743e 418b 1488 ?1.H......t>A... 00000100: 4421 ca45 8b5c 8804 4489 db81 e3ff ffff D!.E.\..D....... 00000110: 7f09 d3d1 eb41 83e3 0143 8b14 9a41 3394 .....A...C...A3. 00000120: 8834 0600 0031 da41 8914 8848 ffc1 ebc3 .4...1.A...H.... 00000130: 480f bfcb 418b 0c88 eb7f 31c9 4881 f98c H...A.....1.H... 00000140: 0100 0074 3b41 8b94 888c 0300 0044 21ca ...t;A.......D!. 00000150: 458b 9c88 9003 0000 4489 db81 e3ff ffff E.......D....... 00000160: 7f09 d341 83e3 0143 8b14 9a41 3314 88d1 ...A...C...A3... 00000170: eb31 da41 8994 888c 0300 0048 ffc1 ebbc .1.A.......H.... 00000180: 8b15 442a 0000 4421 ca8b 0d7f 2000 0041 ..D*..D!.... ..A 00000190: 89cb 4181 e3ff ffff 7f41 09d3 89ca 83e2 ..A......A...... 000001a0: 0141 8b14 9233 1593 2600 0041 d1eb 4431 .A...3..&..A..D1 000001b0: da89 1513 2a00 0031 dbff c389 cac1 ea0b ....*..1........ 000001c0: 31ca 89d1 c1e1 0781 e180 562c 9d31 d189 1.........V,.1.. 000001d0: cac1 e20f 81e2 0000 c6ef 31ca 89d1 c1e9 ..........1..... 000001e0: 1231 d189 c289 0c96 ffc0 3d00 0800 000f .1........=..... 000001f0: 85f5 feff ffba 0020 0000 4889 f80f 0531 ....... ..H....1 00000200: c0e9 e4fe ffff 0000 0000 dfb0 0899 ..............
20 March:
Applying any sort of entropy coding to lzw output seems like a lot of pain. Nominally you have a lot of invariants like e.g. US-ASCII packets that you could efficiently use FSE for to get a double digit CR, but the match packets (>256 + 2 for table clear and promotion) are so just random. the “simple” scheme of inserting trash into the LZW dictionary on almost every byte is moot and you end up with some sort of weird 16-bit alphabet to compress with sparse entries which occur once or twice per block. and then there’s the invariant that all the values are <= than currently seen maximum since last table clear, which UNIX “compress” seems to use for some sort of primitive entropy coding where you begin with 9-bit codes, promote all the way up to 16-bit codes and then freeze the dict and scrape it up when CR drops below delta of 1-3%. for purely technical reasons my program seems faster/stronger than unix compress but it’s a low bar. there’s nothing you can really do with this format, i can see why people ditched it in the 90s and never came back. … but now i’m reading up on some interesting schemes like LZW with 12-bit dictionaries that are selected by o0…o3 context and it clicked in my head that LZP/ROLZ are basically LZW, also looking into some other variations on LZW. probably won’t figure out a nice way to do EC on the LZW output though.
17 March:
weird:
fwrite(&x,1,2,out);significantly slower thanfputc(x>>8,out)and thenfputc(x&0xff,out);- glibc 2.37-15.1. some afterthought: maybe not so weird after all.
14 March:
Hoping to get the very first draft of my whole book printed today. With all the changes to reducing the font and diagram size (to 9pt) it’s 110 pages now.
12 March:
USB-C charging ports = planned obsolescence.
8 March:
Copilot-generated spaghetti left unchecked does almost as much damage to a codebase as an experienced Haskell programmer.
2 March:
The reason why we patch most buffer overflow vulnerabilities is not because they’re a potential RCE. You can’t reliably exploit most of these bugs to get a RCE. The real reason why they’re fixed is that they provide surface for a DoS attack. There’s negligible difference between a heap buffer overflow leading into a segfault and a
panic!("Out of bounds.").
January 2024⌗
14 January:
Bzip3 running on my boyfriend’s PC-98 (486, 66MHz). It seems to work when the block size is set to 1MB and compresses at 22KB/s. The performance can likely be improved.
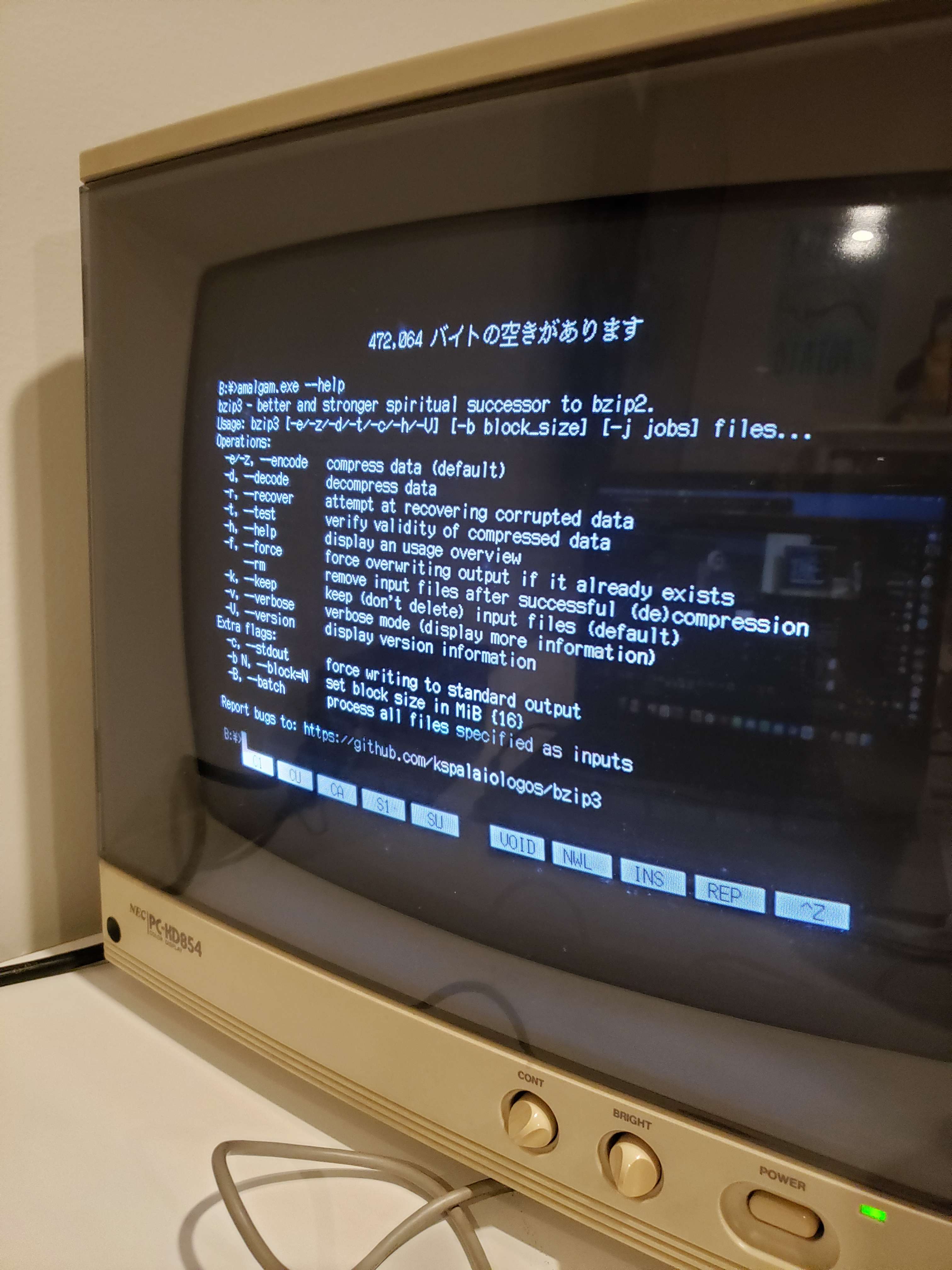
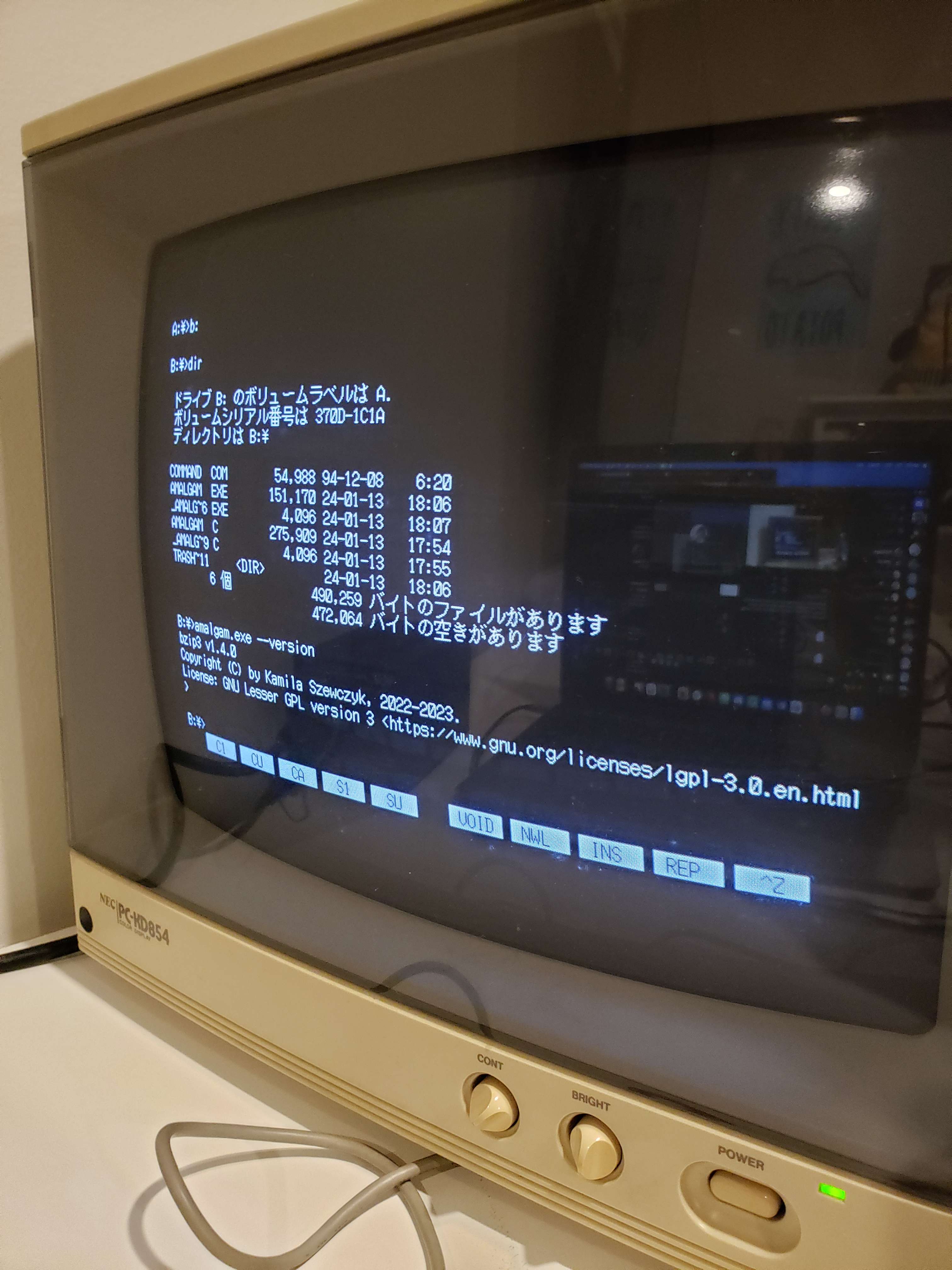
5 January:
Feelings on GregTech New Horizons so far (got only to around midway LV, may not be representative of the modpack as a whole):
- I generally dislike the ore chunk mechanism; it makes it either too easy to obtain resources (encouraging manually digging out the chunk once you found the one you need) or too difficult (can’t find the one chunk that you need).
- The threshold to being able to stop manual labour and start automating things is rather offputting, given the amount of stuff that needs to be done and manually crafted to do some elementary automation with steam age tools is very time-consuming.
- A lot of things that were familiar to me from mods (BC pipes, IC machines, RP circuits, etc) are no longer available. Me no likey.
- The amount of grind required to get to Thaumcraft and other fun mods is absurd.
December 2023⌗
12 December:
People who think that
is better than
Can not be trusted.
10 December:
Getting slowly bored of AoC. Too many uninteresting, cookie cutter imperative problems.
9 December:
I wish mailing lists were more common. E-mail feels a bit like a forgotten medium to me, but it helps me stay organised and safe with OpenPGP signing & encryption.
November 2023⌗
18 November:
9 November:
Interesting benchmark results for general-purpose data compressor performance on Brainfuck code (compiled tiny_sk from the asm2bf distribution):
% wc -c * 29446 tiny_sk.b 1188 tiny_sk.b.br 1405 tiny_sk.b.bz2 1368 tiny_sk.b.bz3 1345 tiny_sk.b.gz 1392 tiny_sk.b.lzma 1097 tiny_sk.b.paq8l 1269 tiny_sk.b.zstRemarkably: While PAQ8L wins, its closest contender is actually Brotli. Then Zstandard, to be followed by gzip, bzip3, lzma and bzip2.
8 November:
Figuratively, trying to bite off twice as much as I can chew sounds like a good way to wrap up the last few years for me. Seemingly, I can chew more and more as time passes. This can’t be sustainable.
July 2023⌗
13 July:
Some musings about register allocation.
Before you read this, remember that this is a highly hypothetical scenario completely disconnected from how CPUs work. Registers do not have to be 8 bytes, there are caches for registers, etc…
Consider a special variant of register allocation where outside of wanting to minimise the amount of spills interprocedurally, we also want to put another constraints on how the registers are allocated. For example, instead of using the first available temporary register as many code generators for MIPS do (unfortunately further away from optimal on x86 due to register requirements for div, etc…); we want to pick a register such that the last referenced register is the closest to the currently considered register. In particular, consider some function f(x, n, m) which models the runtime of the two operand instruction being currently executed. Long division p <- p/q has the computational complexity of O(q^2), hence our function f(x,n,m)=(xm)^2, where x signifies the cost of loads from p and q. Loading Q after having loaded Q again is cheap (caching), but loading P after having loaded Q or vice versa is more expensive. The cost x is defined as |R_p - R_q| - i.e. the distance between two registers in the register file. This may come useful in scenarios where registers are large and the computer has multi-level cache that quickly evicts unused data and eagerly caches new data.
For example: div r1, r4 has the cost factor |1-4|=3 further applied to the worst-case (r4)^2 amount of operations - the instruction would take 3*(r4)^2 cycles. The cost factor of div r2, r1 would be only |2-1|=1, hence the instruction takes only (r1)^2 cycles.
Hence the question posed is: What is the most efficient algorithm to model this particular register preference? The answer to this question would probably provide answers to other similar questions regarding register preference that are ubiquitous on platforms where the exact register you choose for a particular variable does matter (e.g. x86; due to how certain instructions like to store output/take input from a hardcoded register).
A crucial thing to notice is that the problem of register allocation with a preference on the closest register available is essentially equivalent to a modified variation of the 1-D Travelling Salesman Problem where every node can be (and is encouraged to be) visited multiple times if possible!
It just so happens that compilers appear to emit low numbered registers, but that’s due to preferential treatment for volatile registers, as used by calling conventions and then coalesced etc. since using a higher numbered (typically where non-volatile/callee-save live) amounts to spill + reload insertion. In graph colouring, one could use a heuristic to select free colours as closest to an already selected colour. Hence the compiler backend developer’s solution to the problem would be prioritising colours closest to the direct neighbours already assigned colours assuming an ordering to the colours, obviously where colours are numbers to produce a non-optimal but relatively good result.
Notice how similar this approach is to the nearest neighbour search approximate solution to the Travelling Salesman Problem. Hence, to connect the dots: I think that this particular solution is the best one considering speed and how close the output is to being optimal. An optimal analogue would be the exhaustive search TSP solution, while a considerably less optimal but way faster in terms of computational complexity option could be applying the Christofides algorithm.
If you are still wondering what is the use of it, I have to disappoint you and refer you to reading and comprehending this article: https://esolangs.org/wiki/Brainfuck
6 July
A good example of this (red: “It’s not that computers are getting slower, it’s that software is becoming less efficient”) on a completely different layer is JS engines. Notice how stuff like V8 is extremely fast and complicated for what it does. If the web ran on QuickJS or PUC-Rio Lua it would be completely unusable. And this all is because of how much awful horrible JS code there is around, so instead of fixing the very obviously wrong code we simply make better interpreters/compilers, which in the long run, is significantly more complicated.
Instead of putting in the effort to write high quality optimising runtimes for functional or formally verified languages which would actually push computing forward in the long run, we keep trying to make a 30 year old, insignificant or even regressive from a theoretical standpoint, language run fast because the code written in it sucks.
1 July:
Regarding the recent WHO decision to classify aspartame as a potential carcinogen, remember that being a hairdresser or eating pickled food according to the medical literature is also potentially carcinogenic.
https://pubmed.ncbi.nlm.nih.gov/19755396/ & https://aacrjournals.org/cebp/article/21/6/905/69347/Pickled-Food-and-Risk-of-Gastric-Cancer-a
June 2023⌗
30 June:
I have just removed 99% of JavaScript code that used to be on my website. The remaining 0.5KB is used for the mobile navbar to work. So, technically speaking, my website is now completely the same as if you disabled JS entirely. And it still has syntax highlighting in blog posts and math rendering. The only exception being the inherently dynamic subpages of my website (the SDL game ports, etc… - these obviously won’t work well without JS)
26 June:
Most people would never tolerate common scams in a physical setting but if you make one small change as to the technology being used, the mentality in some people changes.
This phenomenon of distancing layers via technology is actually really common; think of how many friends you have that would never fall for traditional multi-level marketing scheme, “get rich quick” scam, penny stock pump and dump, but then if you change the technology to, say, cryptocurrency, then some of those red flags just subconsciously go away. I’ve seen real-life examples of people who on one hand are aware enough to say all these influencers trying to shill this penny stock just want to pump and dump me but then later on they say “Yeah, I really do think that this doggy themed token with no utility whatsoever is going to become 100x more valuable so I better get in quick!” and you might even know somebody who went “I’m not going to give this RuneScape scammer my go- oh my goodness Obama’s doubling my Bitcoin on Twitter!!”.
So many new scams are just old scams with new technology because of this very same psychological distancing barriers that we subconsciously create.
25 June:
It would be nice if IRC didn’t die and someone came up with ways to extend the protocol to support E2EE and other stuff.
I remember being a pretty happy and frequent IRC dweller back in maybe 2019, but it has only gone downhill since (when it came to activity, quality of discussion, the entire freenode drama, etc…) and because I haven’t made that many particularly good friends, I didn’t end up being invited into mid-sized private networks which to my knowledge still thrive and do surprisingly well considering that they are IRC. I can only imagine a similar fate has met XMPP.
OTOH, most quality internet places are slowly moving away from centralised services and slowly dig themselves underground. It’s getting harder and harder to tell AIs apart from humans, some of my friends are particularly paranoid about their messages being used to train LLMs. Internet is slowly becoming an useless sea of spam again.
My main issue with python is the GIL, mess with venvs and other nonsense, bad performance. Python itself is not very embeddable, lacks a proper “type” system. It would be nice if we had some sort of an unintrusive typing system that would help to catch a lot of embarrassing mistakes we make while writing js/python/lua/other untyped languages; I feel like gradual typing from TS actually solves this problem pretty nicely!
A reasonably fast lisp/scheme built on top of a lua-like VM with a gengc & jit compiler + gradual typing of TS and a ground-up implementation of a rich standard library that doesn’t make the programmer reinvent hashtables, graphs or linked hashsets would also be nice. To me what makes a scripting lang good is reasonable (not C-level but still okayish) performance, a substantial amount of software you can graft code from to speed up development (see: python’s ecosystem), some sort of largely inference-based static verification with minimal amount of decorators and other crust to prevent certain classes of errors in the runtime, etc.
20 June:
A gentle reminder of the still unsolved issue that I had with the Linux Kernel ever since I started using a M.2 drive:
If you use LUKS to encrypt a M.2 SSD drive and then perform intensive I/O from within the system, it is going to lock up your entire machine. Impressive, isn’t it?
Debian has dm-crypt worker I/O queues enabled by default and they’re written very poorly, so the kernel waits until they are full or near-full before trying to sync them to the disk, and with multiple queues all fighting for disk access, the disk dies under the load and the system locks up. Now, a linux nerd is going to cry me a bucket of tears that the queues are written perfectly with no flaws whatsoever. The problem is that i don’t care, whatever iotop shows is the truth revealed.
I also can’t run any of my VirtualBox VMs because of this bug in VBox reported 10 years ago: https://www.virtualbox.org/ticket/10031?cversion=0&cnum_hist=14. Obviously, VBox hates I/O latency and eventually gives up if access to the host’s storage takes too long so the hypervisor turns back around to the guest VM and says that the read/write is impossible and the Windows instance in the machine randomly bluescreens.
Situations like these make me miss Windows pretty badly. Shame that W8, W10 and W11 are essentially spyware unless you go through heights to debloat them.
19 June:
Calling all C language lawyers for help: I am wondering whether empty structures are allowed or not. assuming either c99 or c11, whichever more favourable. To quote the standard,
6.2.6.1 Except for bit-fields, objects are composed of contiguous sequences of one or more bytes, the number, order, and encoding of which are either explicitly specified or implementation-defined.
This could imply that an empty struct has a non-zero size (so a C++ like behaviour), however, 6.2.5-20 says: “A structure type describes a sequentially allocated nonempty set of member objects”. So I thought that I can circumvent it the following way:
struct { int dummy: 0; } variable;One would have to remove the declarator, yielding
struct { int : 0; } variable;, per 6.7.2.1.4: “The expression that specifies the width of a bit-field shall be an integer constant expression with a nonnegative value that does not exceed the width of an object of the type that would be specified were the colon and expression omitted.) If the value is zero, the declaration shall have no declarator.”So finally, whether we can have empty structs or not depends on whether int : 0 counts as a member object, but i can’t find anything that would be conclusive on this matter. I have already observed that the C standard treats zero size bit-fields specially, but the only relevant bit of information I could find was 6.7.2.1.12: “As a special case, a bit-field structure member with a width of 0 indicates that no further bit-field is to be packed into the unit in which the previous bit-field, if any, was placed.”
Any ideas?
N.B. the wording in 6.7.2.1.4 says “non-negative”, not “positive”, meaning that the width of 0 is technically allowed as a “normal” width.
May 2023⌗
5 May:
This has to be the most curiosity-inducing error messagge that I have seen in a long while.
In static member function ‘static constexpr std::char_traits<char>::char_type* std::char_traits<char>::copy(char_type*, const char_type*, std::size_t)’, inlined from ‘static constexpr void std::__cxx11::basic_string<_CharT, _Traits, _Alloc>::_S_copy(_CharT*, const _CharT*, size_type) [with _CharT = char; _Traits = std::char_traits<char>; _Alloc = std::allocator<char>]’ at /usr/include/c++/12/bits/basic_string.h:423:21, [...] /usr/include/c++/12/bits/char_traits.h:431:56: warning: ‘void* __builtin_memcpy(void*, const void*, long unsigned int)’ accessing 9223372036854775810 or more bytes at offsets -4611686018427387902 and [-4611686018427387903, 4611686018427387904] may overlap up to 9223372036854775813 bytes at offset -3 [-Wrestrict] 431 | return static_cast<char_type*>(__builtin_memcpy(__s1, __s2, __n)); | ~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~Turns out that this is actually a compiler bug - https://gcc.gnu.org/bugzilla/show_bug.cgi?id=105329 and the comments on this thread are awesome. Creating a new string instance using the (int n, char c) constructor basically causes warnings to break due to some issue with Ranger, it’s been a known bug for 2 minor versions of GCC, and there is no good fix for it. And you need a PhD in compiler design to understand why.
April 2023⌗
18 April:
Realisation: When I was working on my ELF infector post, I once didn’t properly sandbox it from the rest of my system. This way I accidentally got cargo and a bunch of other binaries infected and when they randomly started behaving weirdly, I finally figured out what was going on and reinstalled Rust.
14 April:
One way to allow RC without a cycle collector would be to enforce an unidirectional heap. And the actor model will surely help in avoiding atomics too.
13 April:
Seems like bzip3 wipes the floor with lzma when it comes to java class files. What if i told you that the size of the average jar you see online could be 2x-4x smaller?
94136320 lisp.tar 6827813 lisp.tar.bz3 13984737 lisp.tar.gz 7693715 lisp.tar.lzma 8292311 lisp.tar.zst 130934896 total
February 2023⌗
16 February:
It’s alive…
13 February:
I have decided to decommission Lovelace (the i5-7400 16G server) and sell it. Primarily because it’s not very power efficient and I can move my services to VPSes anyway.
9 February:
An interesting method of computing permutation parity using the 3-cycle composition property:
Unsurprisingly, translates horribly into array logic languages. I wonder how would I implement it in my Lisp…
January 2023⌗
14 January:
A (hopefully) interesting idea: A virtual machine with a rich standard library and instruction set, procedural, functional, based on the Actor model. I plan to use only reference counting and cycle collection, have it be variable-based (no manual register allocation and no stack to make matters worse). Fully immutable, but it’s possible to implement functional data structures using a cute way built into the interpreter. Likely JIT-compiled using either cranelift or llvm. Can send code over the LAN or even the Internet for transparently parallel execution. Provides some cute utilities for number pushing; completely statically typed and ideally the code is monomorphised before being passed to the VM.
December 2022⌗
20 December:
I hate programmers who have very big mouth and tunnel vision eyes that together jump to form the most radical and nonsense views I have seen in my life. And nothing to back their redundant opinions with.
8 December:
Having implemented the Lerch transcendent and Riemann zeta, now it’s time for the Hurwitz zeta. Technically speaking, the Lerch transcendent is a generalisation of the Hurwitz zeta, so that ζ(s,n)=L(0,n,s)=Φ(1,s,n); However, my implementation of Lerch phi (which is still not as efficient as I’d like…) computes the upper incomplete Gamma function value as a factor in the final result, and when z=1 a!=1 we stumble upon a funny case where the upper incomplete Gamma function has a complex pole /yet/ the Lerch phi is defined at this point (as of course the Hurwitz zeta).
The game plan now is to implement a somewhat general Euler-MacLaurin summation function and derive the formula for the n-th derivative of the Hurwitz zeta function with respect to s (which should obviously be trivial) to speed up the “general” method.
This will have an interesting consequence: We can compute an arbitrary derivative of the Hurwitz zeta at any point we wish, meaning that computing the Glaisher constant defined in terms of the derivative of zeta at some integral point will become attainable.
The pieces of puzzle in SciJava are slowly coming together.
November 2022⌗
11 November:
I tasted vanilla Chai Tea for the first time in my life! And the first thing I did after coming back home from uni cafe was to try making it myself at home. Turns out i packaged some ginger when i moved, i had some cinnamon and i bought honey on my way home. I made it and the taste was rather mild and I realised that the tea I brewed from the leaves was too strong. Better luck tomorrow I hope.
August 2022⌗
30 August:
Taking another look at it, I feel like MalbolgeLISP (especially v1.2) might be the best thing I made in my life. It’s so weird to think that it’s been a year now…
29 August:
My thinkpad arrived today! Just E14 with a Zen 3 Ryzen 5 and 16G of RAM. Initially had a few issues with making it boot off USB and getting networking to work, but now it works pretty good and I’m happy with it.
May 2022⌗
23 May:
Good and bad news!
First, my compressor is assymetric now. The bad news is that it’s assymetric the wrong way around - compression is quite a bit faster than decompression…
4 May:
Once in a while, the circumstances allow to use the goes-to operator…
March 2022⌗
22 March:
I love nixie tubes so much. So sad they’re gone now.
4 March
February 2022⌗
11 February:
The Level 0 kernel simulates basic operations of the 68020 processor on which PARI was originally implemented
4 February:
Today’s interesting algorithm: the Entombed maze generator.
3 February:
Just finished: “Heart of Darkness” by Joseph Conrad.
2 February:
https://en.wikipedia.org/wiki/Kateryna_Yushchenko_(scientist)
1 February:
“This will be demonstrated using BBC BASIC (a language which beautifully expresses the mathematical structure)”.
January 2022⌗
30 January:
Back when I was a Windows user, I loved http://setedit.sourceforge.net/.
December 2021⌗
23 December:
I checked my VPS today out of boredom. Turns out that we have a new record, 5871 bytes for a ski combinator calculus reduction thingy in Seed.
22 December:
Usefulness to the society isn’t a good objective metric. It erases people who are useful to the society in a non-obvious way.
9 December:
Leah (the Void Linux maintainer) gifted me an Aeropress for Christmas :).
1 December:
November 2021⌗
28 November:
26 November:
Feeling bad about my cup size. Pads don’t seem natural enough.
25 November:
I’m mostly bleeding out my sanity and soul, but I’m holding on for a single reason.
24 November:
I just back off social contacts and try to minimise my exposure to other people without actually wanting or needing (i think) it. I’m not sure why this even happens.
21 November:
I’m perpetually uninspired.
19 November:
About the binomial theorem. When we did this in class, our teacher wanted us to find the coefficient of the Nth term, and I could find it really quickly in my head, which greatly impressed him. He gave us three middle coefficients of (x+y)^8 (hence showing 3,4,5 choose 8) and wanted us to compute the middle coefficient of (x+y)^9 (4 or 5 choose 9). This is simple:
C(n,k+1) = C(n,k) * (n-k) / (k+1).
18 November:
I am deeply unhappy with western math curricula. Teaching integrals before derivatives. Teaching trigonometry without the unit circle. Teaching integration without riemann sums. Teaching probability without it’s axiomatic definition. Teaching calculus before basic stuff which isn’t calculus. People have an unhealthy obsession with calculus - wow! derivatives, wow! integrals - and then you see a clueless person who sees a quadratic-related problem and can’t solve it but they can give you an indefinite integral of x^2 or tell you what a conjugate of a given complex number is equal to.
17 November:
I’ve been made for greater things than shuffling numbers around.
16 November:
Wealth inequalities are the root cause of most inequalities in our contemporary society.
11 November:
⊣×∘~⍴⍤⊣⍴⍸⍤⍷⍨(⍸⍣¯1⍤,∘.+)⍳⍤⍴⍤⊢.
8 November:
The guy with an incredibly ridiculous caricature as his only depiction. (Legendre)
August 2021⌗
12 August:
My favourite pair of short shorts no longer fits me.
10 August:
Minor medication shortages.
July 2021⌗
18 July:
First trials of MalbolgeLisp 1.1 have started.
5 July:
Remembered about https://pastebin.com/qt05TvEP.